Project Description
KnowText poster
 MARKET NEED
MARKET NEED

There is an information overload from unstructured text used as business leads (knowledge on customers, markets or technologies) from which users need to find the Facts: the relevant Entities, the Links between Entities and their evolution.
Extracting practical information from text is a complex task requiring human understanding of semantics. The Knowledge Graph (KG) technologies bring a competitive edge as part of the Semantic Web. KGs can capture the network of Relationships between Entities in a graph structure, while also building a Knowledge Base (KB), designed to enable automated reasoning.
Existing open-access industrial knowledge graphs have mapped billions of entities from large scale web data and use as KB various expert-built ontologies, graph databases or triple stores. The use of wide scope platforms require expert knowledge and can be time and computationally expensive – as very large KG become difficult to query, while domain-specific understanding of text may require generating new models.
TECHNOLOGY SOLUTION
The KnowText demonstrator performs automated Knowledge Graph extraction from a collection of texts and enables users to visualize and query the KG and its background ontology. Facts extracted as <Subject, Predicate, Object> triples are represented as a graph and linked to an automatically extracted OWL Ontology featuring 15 Classes of Named Entities and one Class for domain vocabulary words, within a basic schema.
Both the extracted triples and the OWL ontology files can be downloaded and further explored.
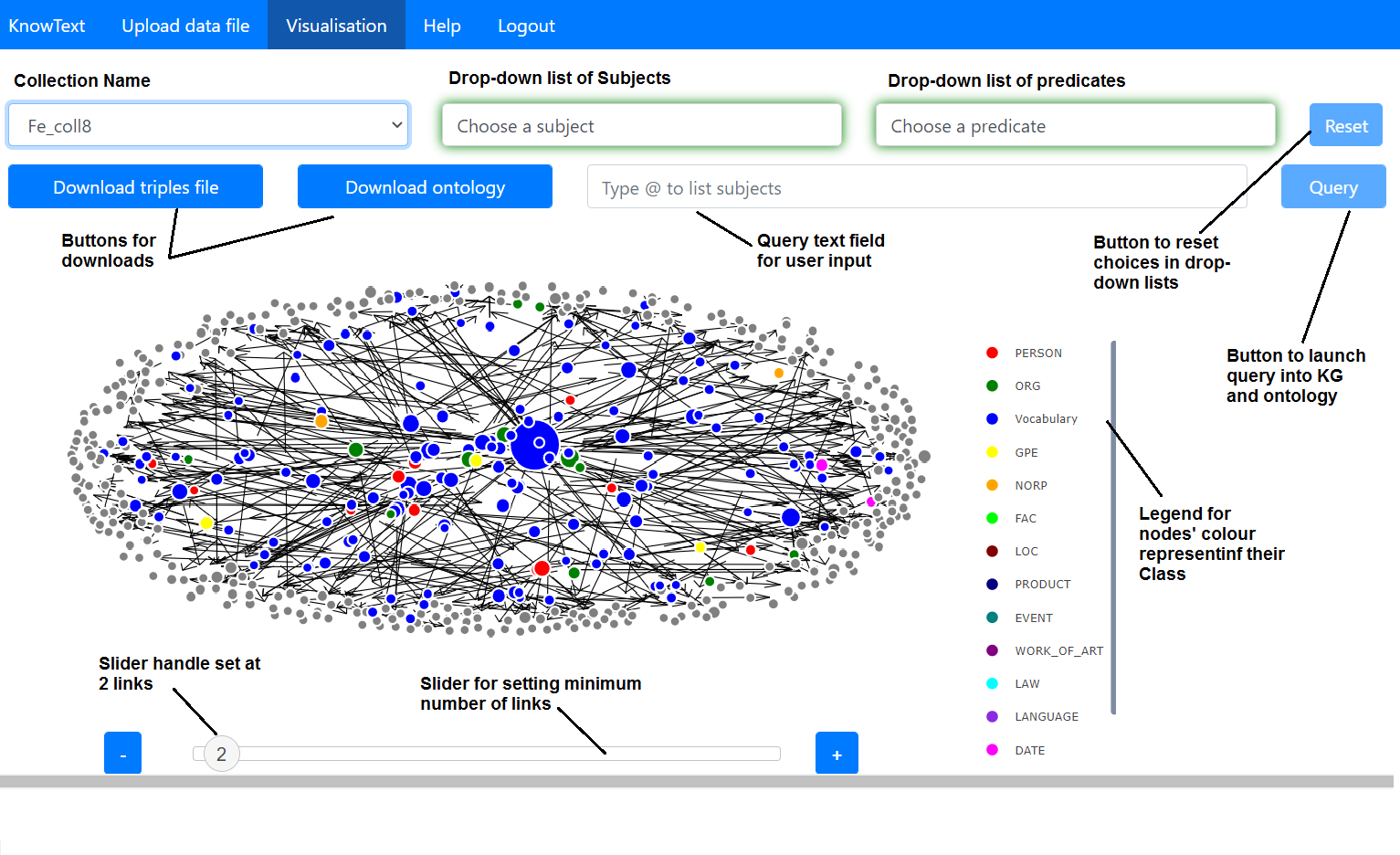
The KnowText visualisation tab, explained.
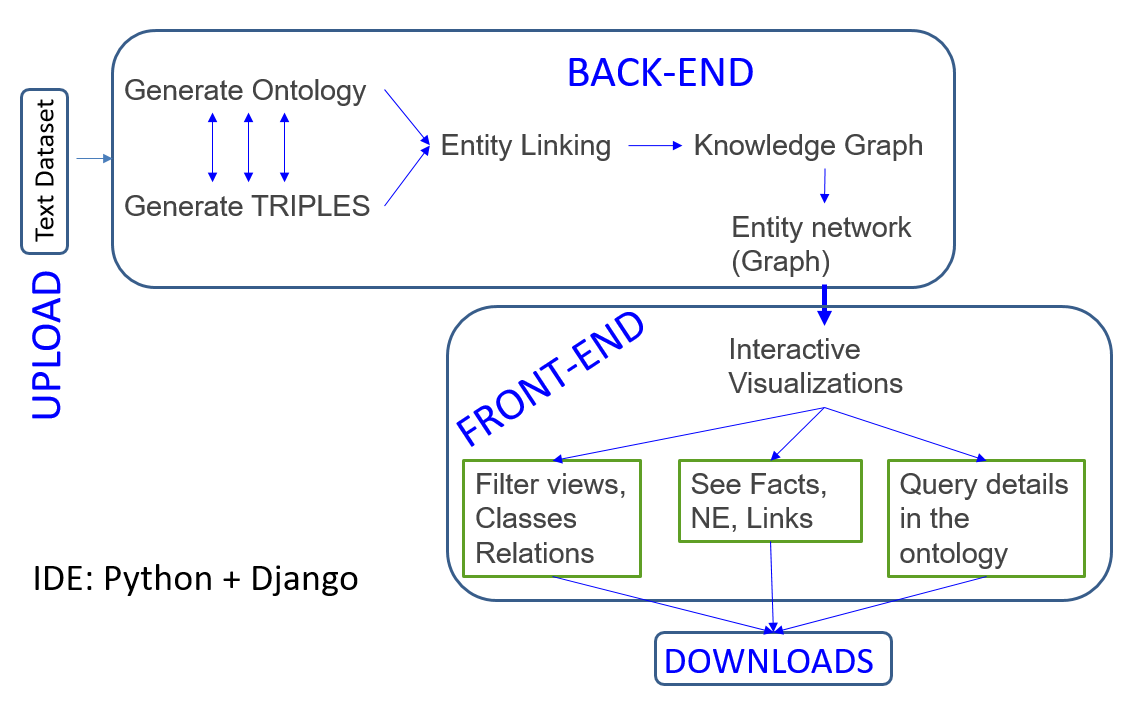
The KnowText workflow.
APPLICABILITY
The KnowText demonstrator provides:
- Automated generation of a domain specific KG (within a company domain of interest) using as information pool only data uploaded by the user;
- Interactive visualisations of the text collection as a Knowledge Graph (filtering & exploration of Entities & facts);
- Easy query methods based on Entities & Relations search or free typed text.
KnowText is a python based web application: portable, flexible, scalable, accessible via a web link, easy to use by non-expert users.
RESEARCH TEAM
- Dr. Bojan Bozic, TU Dublin
- Dr. Tamara Matthews, TU Dublin
- Mr. Jayadeep Kumar Sasikumar, TU Dublin
- Mr. Abhimanyu Gangwar, TU Dublin